UTFS a Tar-like File System for Embedded Systems
June 2025
In this article we are going to look at UTFS, the Micro Tar File Systems, a small embedded file system structure developed by CLI Systems.
Check it out on github.com: https://github.com/clisystems/utfs/
UTFS is a method for organizing data on storage medium with flat address space using string based file names, separating the data storage details from the application level data structure, and includes features to allow the data size and position to change without data loss.
UTFS is designed for read, update, write operations, with limited facilities for streaming or appending operations.
The Problem
Almost every embedded system needs to store data in to non-volatile memory. Common examples include serial number, configuration parameters, and feature settings.
Microcontrollers can access raw flash/EEPROM easily, and a common solution is to use a fixed data structure with these parameters read at boot, and written when a parameter is changed.
This solution works, but has some severe limitations which affect the structure of the firmware.
Take the following example with a common data storage structure, and four source files with multiple pieces of data
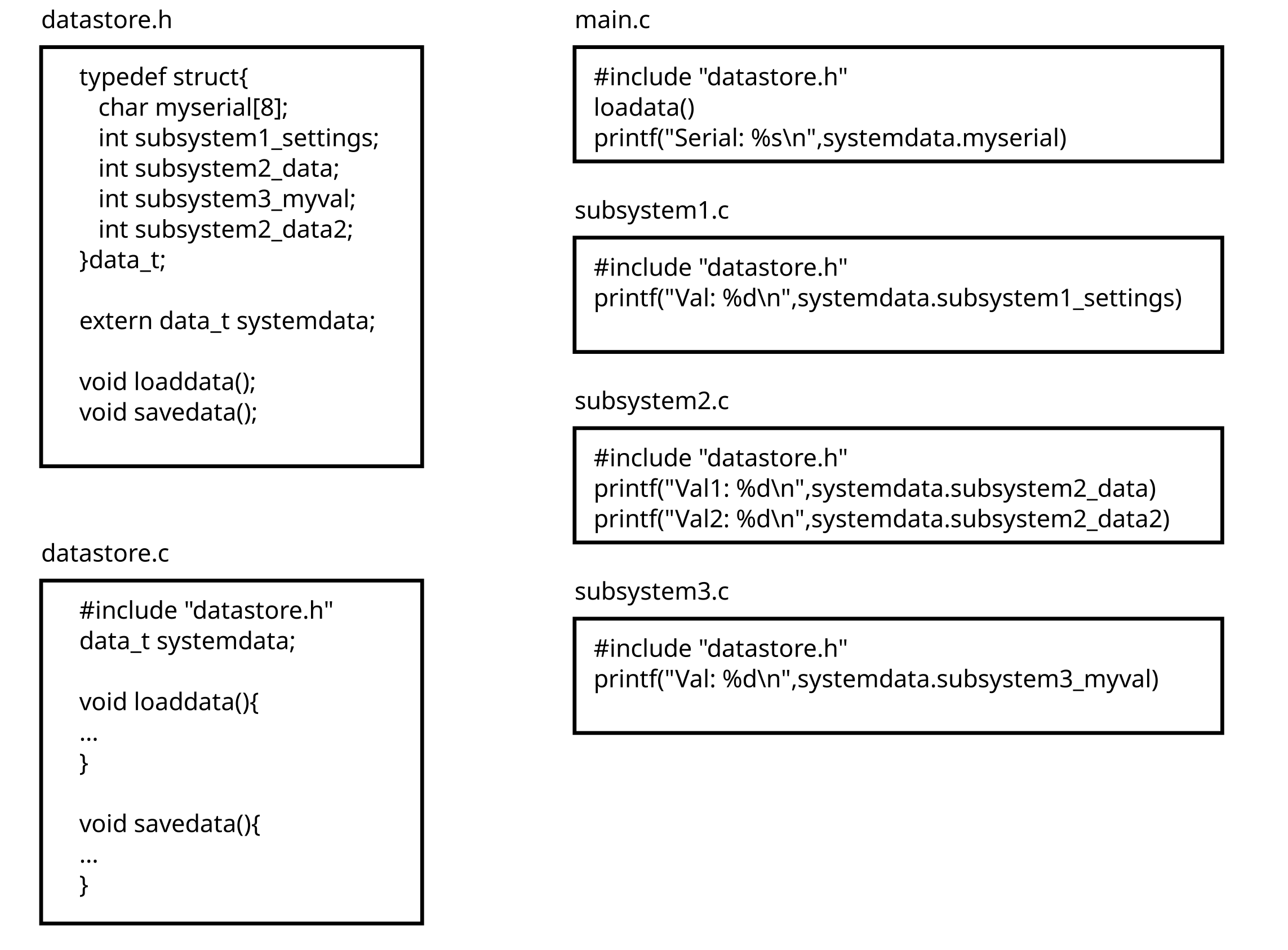
There are a few problems with this method:
- The application logic is tightly coupled with the data structure The data storage structure is defined inside the datastore.c source, and an extern is provided in the header to make the data structure globally accessible. This method tightly couples all of the code to the data storage structure, any change to the structure could cause the subsystems behavior to change. Also, any change to the structure will cause a recompilation of the sources that include it.
- Unrelated code can modify the data Buffer overflows could affect sections of the code that are unrelated. Imagine if a new serialnumber was set using:
- Structure is very rigid In the example we see serialnumber is defined as 8 characters, but what happens when the business requirements change, and the serial number must now be 16 characters? Commonly the data would be relocated to a new section of the data structure and the original 8 bytes are unused:
- Variable names are very rigid If the global systemdata variable, or one of it’s member variables, is renamed, then every single piece of code that references it through the whole firmware would have to be renamed. This is poor design practice, the internal structure of unrelated sources should not affect the code of other sources in the system.
sprintf(systemdata.myserial,"000000123400")This sets a new serial number of 12 characters to a buffer that is only 8 characters wide, which will set the value of subsystem1_settings to something like 0x33343030, and subsystem2_data to 0x00###### . This overflow of the serial number could cause an unrelated subsystem to behave incorrectly, creating bugs that are very difficult to trace.
Buffer overflow is an inherent problem with C, but having data as isolated as possible reduces the likelihood of this class of bugs.
The example above also highlights what can happen when data is added in different orders. Subsystem2 added ‘data’, then subsystem3 added its ‘myval’, but later subsystem2 needed to add ‘data2’. Since the variable for subsystem3 could be on the storage medium from previous releases, the new variable is added after the existing one. This results in a fragmented structure with all data interleaved. As the structure grows over time and features are added and changed it becomes apparent what a mess the organization becomes.
The UTFS Solution:
UTFS started as a effort to separate the data storage of different subsystems, where one subsystem could be updated or changed, and the other sources in the system do not need updates.
Isolating subsystems requires a method to identify the correct datablock for that subsystem, this requires an identifier such as a string; aka, a name for the file.
As we explored options, we were reminded that this problem has been solved before, back in the 1970s with tape drives. Tape drives are flat memory address space storage mediums, with no facility for random access writing. The TAR file format was a way to store data on these flat memory spaces in different files. The TAR archive format has a 512 byte header which stores all the information about the file, and then the file is written in 512 byte blocks. Subsequent files are appended with a header and then data, one after another.
Combining the base concept of a TAR archive with pointers to memory blocks allows for storage and retrieval of arbitrary data, completely independent of the source code implementation.
Unique Characteristics of UTFS
As we worked on a solution for UTFS we re-evaluated the common open, read/write, close paradigm that is used in modern file systems. The opened vs closed nature of files is primarily related to streaming or appending data to a file, and does not align ideally with a load-modify-save paradigm. Because of this, UTFS does not have open and close functions, all data is loaded in to RAM, or saved from RAM on the storage medium.
While TAR might be a simple format, the blocks and header are still 512 bytes, which could be a large percentage of a microcontroller’s RAM or an EEPROM’s size. Because of this, it was decided to store only the minimum amount of information in the UTFS header. To keep the header on octal-boundaries, the decision was made to make the header 24 bytes, and allow for 12 bytes for a ‘file name’, which is a maximum file name length of 11 bytes plus the C string NULL terminator (\0).
The UTFS header contains a 16bit signature variable. This variable is for the application to set, to allow for different version management. The signature byte is automatically loaded and saved with the data, so no additional information needs to be added to the data structure inside the file.
Interface
The UTFS interface is based on pointers to blocks of RAM data. When the UTFS file system is loaded, if a file matches a file name, that data is loaded in to the RAM data.
In the example below, the three subsystems all have unique data, and the structure of each does not affect the other.
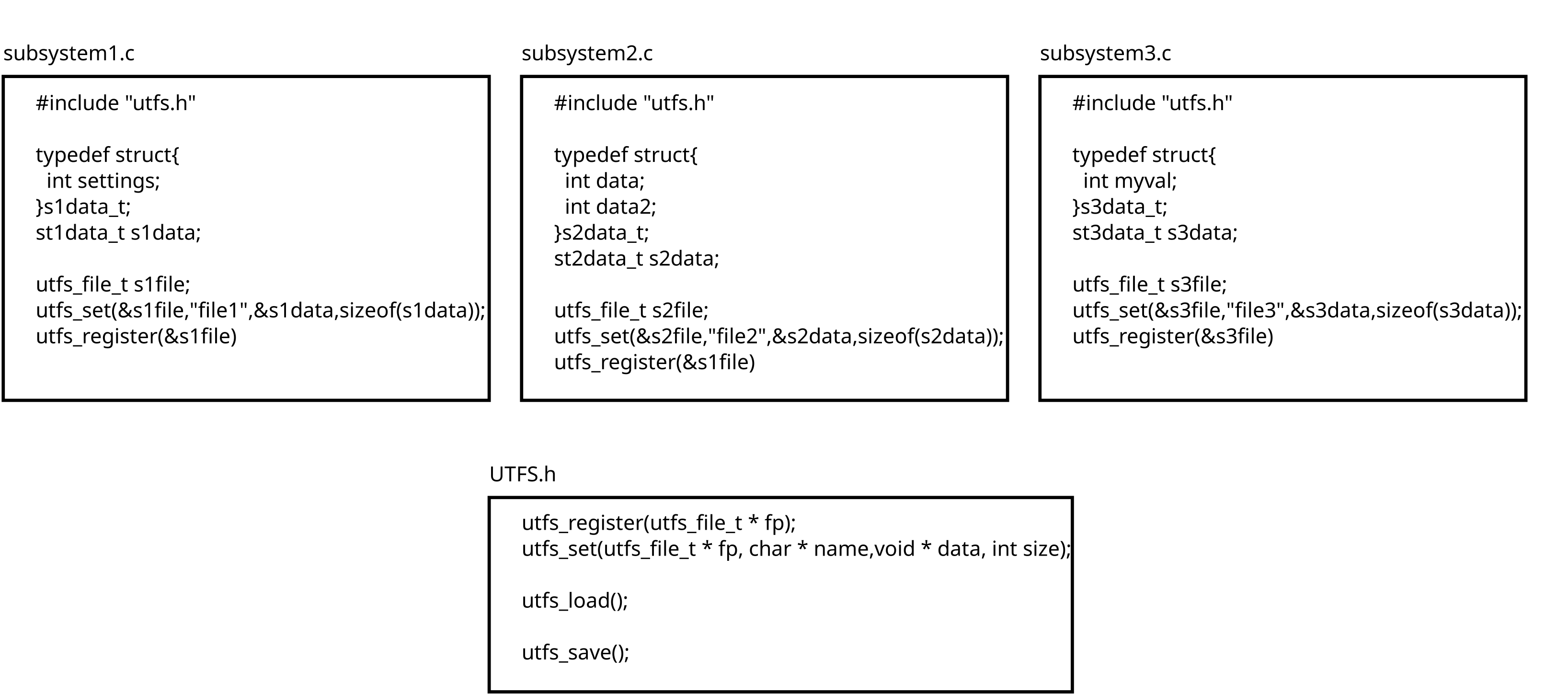
Once the utfs_load() function is called, all data is loaded from the storage medium and the data is loaded in to the RAM data structures.
Data in the RAM structures can be modified by the application as needed. When the data is required to be saved, a call to utfs_save() writes all data to the storage medium.
Changes in data sizes
Data structures change all the time, typically as business requirements change or features are added.
If a data structure in RAM is smaller than the file data on the UTFS storage medium, only the size of the current structure in RAM is loaded. This prevents overflow of the RAM structure.
If a data structure in RAM is larger than the file data on the UTFS storage medium, only the size of the UTFS file data on the storage medium is loaded.
Changes in the data structure size only affect the data loaded by UTFS. When a utfs_save() is executed, the current size of the data structure in RAM is written to the storage medium. This allows for data structures to change size, and since the entire contents of the file system are written at one time, all data automatically adjusts position.
In this example you can see three revisions of the data saved to the storage medium, where data structures sizes change each time. When utfs_save() is called, all data is automatically aligned on the storage medium without data loss.
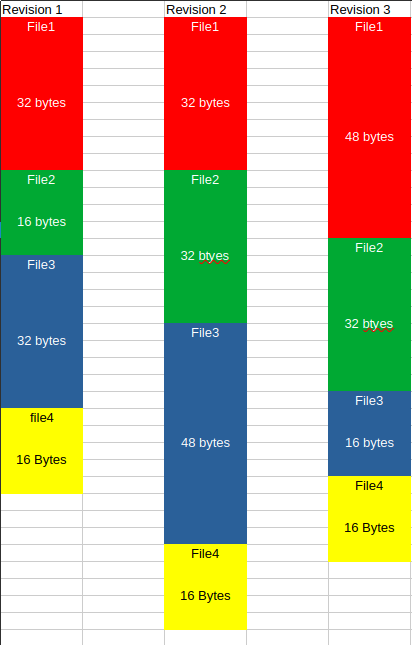
It is up to the application to detect different file sizes (aka revisions) and upgrade the data in the structure accordingly. See the Best Practices section related to use of the signature variable.
Best practices
It is recommended that the application use the built-in signature variable in the file header to manage versions of the stored data. The signature variable is a uint16_t that is saved with the file data. Using the signature variable, the application software can validate the data, or upgrade the data from one version to a newer version.
In the following example, the signature value is used to determine which version of the data was loaded from the storage medium:
struct datav1{
char serialnumber[10];
char modelnumber[10];
};
struct datav2{
char serialnumber[16];
char modelnumber[16];
};
typedef union {
struct datav1 data1;
struct datav2 data2;
}data_u;
uint8_t buffer[sizeof(data_u)+1];
data_u * sysdata_buffer = (data_u *)buffer;
utfs_file_t sysfile;
// Register the UTFS file
utfs_set(&sysfile,"system",buffer,sizeof(buffer))
utfs_register(&sysfile);
// Load the UTFS data
utfs_load();
// Check the signature after the data for the
// version
if(sysfile->signature == 0xA1){
printf("Data is v1\n");
}else if(sysfile->signature == 0xA2){
printf("Data is v2\n");
}else{
printf("Data unknown version, making it 0xA2\n");
memset(buffer,0,sizeof(buffer));
sysfile->signature = 0xA2;
}The signature variable is purposefully not named 'version' since the signature of the data may be used for other purposes than versioning, such as a data checksum. This option is up to the application developer.
Integration with existing data storage
Existing, legacy, firmware is typically a difficult situation to work with. The firmware is running out in the field, and the data stored on the storage medium typically can not be lost.
The developed UTFS interface allows for setting the ‘base address’ of data in the storage medium. This allows the UTFS system to define where data starts, which could be located away from existing data storage.
In this example, the existing data store is at address 0x00000000 and the UTFS system base address is 0x00001000, well beyond the existing data store.

Conclusion
Overall, UTFS provides a simple method to load and store data from non-volatile storage in to RAM, while decoupling the data storage structure from the application level code. It is designed to be integrated with either new or existing systems, and provides a low-overhead RAM and flash method to organize data
The UTFS code on github is released under an MIT license, so please use it and feel free to send any changes or comments on github.
https://github.com/clisystems/utfs/